
Jose Hernandez
9 Months Ago
Modern businesses are generating and leveraging more data than ever before, with 97% of organizations investing in big data and AI to make better, faster decisions. But at the same time, there’s increasing pressure to control costs. More than 80% of IT leaders are being asked to cut cloud spending, even though the demand for advanced data platforms continues to rise.
This creates a challenge for companies: how to manage and analyze large amounts of data while keeping expenses in check. With different storage options available—like data warehouses, data lakes, and the emerging data lakehouse—businesses have to decide which approach best fits their needs.
So, what exactly is a data lakehouse? How does it compare to traditional data warehouses and data lakes? And why are so many organizations starting to adopt it?
Let’s take a closer look at these different data storage solutions and why the data lakehouse might be the right choice for your business.
What is a Data Lakehouse?
A data lakehouse is a modern data platform that combines the key features of both a data lake and a data warehouse. It integrates the flexible storage of unstructured data from a data lake with the strong management and performance capabilities of a data warehouse. By doing this, a data lakehouse allows businesses to store, manage, and process all types of data—structured, unstructured, and semi-structured—on a single platform.
In simple terms, it takes the strengths of both systems: the ability of a data lake to store large volumes of diverse data, and the organizational tools of a data warehouse that make it easier to manage and analyze that data. This combination helps data teams work more efficiently by reducing the need to move data between two separate systems, which also speeds up tasks like analytics and machine learning.
Data Lakehouse vs. Data Lake vs. Data Warehouse
Before we explore the details of a data lakehouse, it’s important to understand how it compares to the more traditional data warehouse and data lake, both of which have played key roles in how companies manage their data.
Data Warehouse
A data warehouse is a system designed to store structured data that has been processed through ETL (Extract, Transform, Load) operations. It is ideal for high-performance analytics, using SQL to generate reports and support business intelligence (BI). The focus is on delivering fast results for structured data, like financial reports or sales trends. However, data warehouses are less flexible when it comes to handling unstructured or semi-structured data, such as images or logs. They can also be expensive to scale because all the data needs to be cleaned and organized before it’s stored.
Data Lake
A data lake is a more flexible storage system that can hold large volumes of raw data in various formats—structured, semi-structured, or unstructured. Data lakes are often used for advanced analytics, machine learning, and AI-driven projects, as they provide access to a wider range of data. However, without careful management, data lakes can become messy and hard to navigate, often referred to as “data swamps." This happens when data is stored without proper organization or oversight, making it difficult to extract useful insights.
Data Lakehouse
A data lakehouse brings together the best of both systems. It combines the flexible, low-cost storage of a data lake with the powerful data management and structure of a data warehouse. Data lakehouses support all types of data—structured, semi-structured, and unstructured—and allow for a range of workloads, from traditional BI reports to more complex machine learning tasks. They also provide features like ACID transactions (which ensure data accuracy and reliability), making them a solid choice for companies that need to handle diverse data types while ensuring data quality.
Key Differences
| Feature |
Data Warehouse |
Data Lake |
Data Lakehouse |
| Data Type |
Structured data |
Structured, semi-structured, unstructured |
All data types |
| Data Processing |
ETL (schema-on-write) |
Schema-on-read |
Schema-on-read and schema-on-write |
| Cost |
High |
Low |
Moderate |
| Workloads |
BI, Reporting |
Advanced analytics, ML |
BI, ML, Advanced analytics, ML, |
| Transaction Support |
ACID-compliant |
Limited or none |
ACID-compliant |
| Scalability |
Limited |
High |
High |
| Governance |
Strong |
Limited |
Strong |
As we dig deeper, it’s clear that a data lakehouse offers powerful features that set it apart from other solutions. So, what makes it so unique, and why is it becoming the go-to choice for many businesses?
Key Features of a Data Lakehouse
Here are the key features of a data lakehouse:
- Single Data Platform: Provides a unified platform to store structured, semi-structured, and unstructured data. It eliminates the need for separate systems for different data types and streamlining data management.
- Open Data Architecture: Supports open formats like Apache Parquet and ORC, allowing flexibility to access and process data with different tools, preventing vendor lock-in.
- ACID Transactions: Like traditional databases, data lakehouses offer ACID (Atomicity, Consistency, Isolation, Durability) compliance, ensuring data integrity and consistency during transactions, even in a multi-user environment.
- Decoupled Storage and Processing: The ability to independently scale storage and computing resources, which reduces costs by avoiding unnecessary overspending.
- Governance and Data Quality: Features like schema validation, auditing, and real-time monitoring help maintain data quality, ensure security, and support compliance with regulations like GDPR.
- High-Performance Querying: Optimized querying with columnar file formats and indexing, enables faster data retrieval and analysis, similar to traditional data warehouses.
- Integration with BI Tools: Direct access to data simplifies integration with business intelligence tools, reducing the need for complex ETL (Extract, Transform, Load) processes.
How Does a Data Lakehouse Work?
This hybrid platform brings together the best of both data lakes and data warehouses, helping businesses handle large amounts of data—whether structured (like databases), semi-structured (like JSON files), or unstructured (like videos or images). The goal is to store, manage, and analyze this data more efficiently and affordably. Here’s a simple breakdown of how a data lakehouse works:
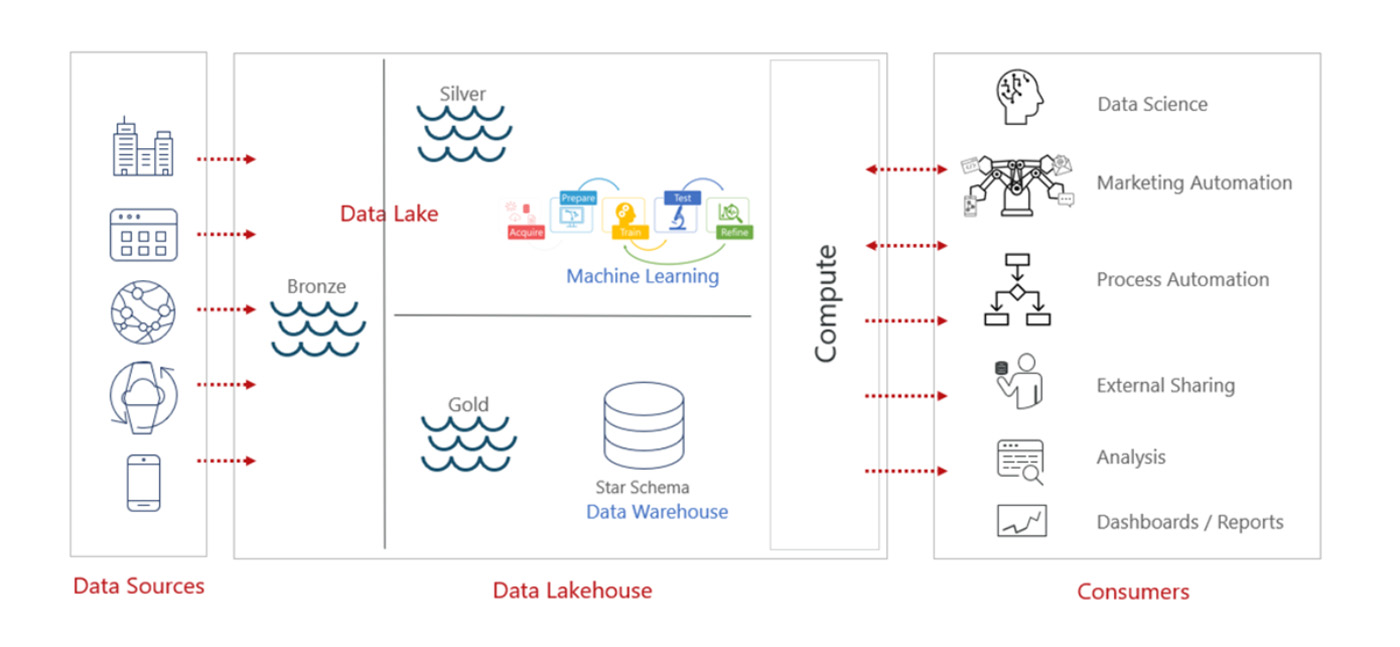
1. Data Sources
Businesses gather data from many places: enterprise applications, databases, IoT devices, mobile apps, and more. All these sources feed into the lakehouse, capturing the data in its raw form, whether structured or unstructured.
2. Data Ingestion into the Lake
Once the data comes in, it's stored in different layers within the data lakehouse based on its level of processing and readiness for use:
- Bronze Layer: This is where the raw, unprocessed data lands first. It's saved exactly as it is from the source and acts as a reservoir of all incoming data. At this stage, the data hasn't been cleaned or transformed yet.
- Silver Layer: In this layer, the data is cleaned and transformed to make it more structured and ready for analysis. This is especially useful for more advanced tasks, like machine learning or business reporting.
- Gold Layer: Here, the data is highly refined and often organized in a format like a star schema (which makes it easy to run queries on). This layer is optimized for high-performance queries and business intelligence tasks, where clean, verified data is needed.
3. Machine Learning & Real-Time Analytics
Once the data is processed in the Silver Layer, it becomes ready for machine learning models and real-time analytics. Data scientists can train, test, and refine their models using both structured and semi-structured data right from the lakehouse. Since everything is in one place, businesses don’t need to move data between different systems, making things faster and more efficient.
4. Compute and Data Processing
The data lakehouse separates compute (the power to process data) from storage (where the data is kept). This allows businesses to scale them independently. So, if they need more processing power or more storage, they can increase one without worrying about the other. This helps them efficiently manage costs while also handling large datasets. Parallel processing (where multiple tasks happen at the same time) improves the speed and performance of data querying and real-time processing.
5. Data Consumption by End Users
Once the data is cleaned and ready, different teams in the organization can start using it:
- Data Scientists can run complex machine learning models.
- Marketing Teams can use customer data to optimize campaigns.
- Automation Systems can use the data to make business operations more efficient.
- External Stakeholders can access shared data if necessary.
- Business Analysts can use the data for dashboards and reporting.
By leveraging this architecture, end-users can access high-quality, processed data for their specific use cases, whether it's real-time analytics, business reporting, or machine learning.
"According to recent research, 65% of organizations are now running the majority of their analytics on data lakehouse"
At this point, you might be wondering: Why are so many organizations investing in a data lakehouse? Let’s take a closer look at why it could be the perfect fit for your organization.
Why Do Organizations Need a Data Lakehouse?
Here are the reasons why organizations need a data lakehouse:
- Reduces Data Silos: Many organizations struggle with fragmented data across multiple systems. This platform brings all data into one place, eliminating silos and allowing different departments to work with the same information, improving communication and efficiency.
- Enhances Operational Efficiency: By offering a scalable solution that can handle large amounts of data, this platform improves operational efficiency. It reduces the need for extra computing resources, helping businesses save on costs and run more smoothly.
- Supports Advanced Analytics: It allows companies to make better decisions by enabling advanced analytics like predictive models and personalization. Marketers can target specific customer segments, and analysts can use real-time data to evaluate and improve marketing strategies.
- Simplifies Data Governance: Managing data across multiple systems can be challenging when it comes to maintaining security and compliance with regulations. This platform includes built-in governance tools that ensure data integrity, security, and compliance with industry standards, making it easier for businesses to meet legal requirements.
- Improves Customer Insights: By consolidating data from different customer interactions, businesses can achieve a 360-degree view of their customers. This helps companies better understand customer behavior, improve personalization efforts, manage risk, and detect fraud.
Contact Dunn Solutions for Help
Ready to get the most out of your data? Contact Dunn Solutions to learn how our team and technology partners can help you build a data lakehouse that meets your business needs. We’ll help you speed up implementation, reduce costs, and simplify the management of your data. Let us guide you in creating a solution that improves your data strategy and supports better decision-making. Reach out to us today!



