This post shares some best practices we have utilized while implementing data warehouses for healthcare organizations participating in a new care model, called Accountable Care Organization (ACO). ACO requires changes in care management and related business processes, including IT enablement. The post will focus on the technology side of the implementation.
Current State of Healthcare in the U.S.
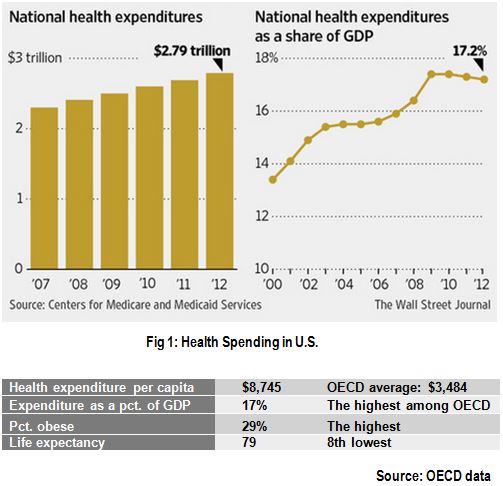
Before diving into the specifics of an ACO model, the following figure highlights the current state of healthcare in U.S, which is primarily a fee-for-service model.
Value-Based Care Model
The statistics above illustrate that even as healthcare spending is rising above the norms, the expected return of a onger life expectance is not. As part of the accountable care act, and other similar initiatives by some insurers, the health care delivery is evolving to a value-based model from the traditional fee-for-service model. The term “fee-for-service” doesn’t imply accountability for outcomes. The new model instead focuses on better patient outcomes at a lower cost of care, through improved coordination and accountability. A group of participating providers create an accountable care organization (ACO), who will share the responsibility for care coordination to manage the assigned patient population efficiently. Care coordination ensures seamless care delivery, which is not the case with the fragmented traditional model. ACO's also follow guidelines for preventive care on outpatient care settings, and performance monitoring and reporting. As a result of meeting the established performance goals, the payers will share (reimburse) the savings generated by the new model with the ACO and their provider partners. In the longer run, a successful ACO organization will have competitive advantages within the healthcare industry.
Data Driven Approach
A broad initiative like ACO, which spans multiple business processes and clinical databases, calls for the underlying data architecture to be scalable and support data discovery. The following sections highlight some important elements of the architecture. Fig 2 below shows how diagnosis data from several sources, both internal and external, are consolidated in the warehouse, and then delivered to the users in a clinically usable format.
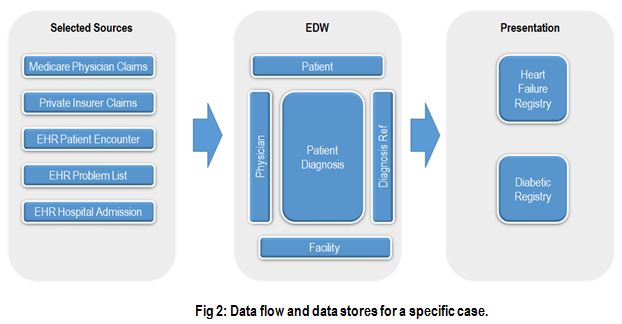
Data integration and a canonical model:
The ACO model relies on the seamless visibility of patient encounters in a broad care setting. All clinical activity should be tracked electronically and shared, not just within the organization, but should also include external providers the patient engages with. Payers, and other participating organizations, share authorized patient data among each other to support a comprehensive view of clinical activity. This view may include patient rosters, provider databases, claims (encounter summary), etc.
The IT department of the ACO may already have implemented a data warehouse structured around its existing EHR systems. In that case, more abstractions may be necessary to provide a platform-agnostic view of the data. If you are planning to implement a new data warehouse, with the ACO model being a driver, this requirement for a canonical model should be accounted for during the design phase. The in-house EHR may structure hospital admissions data in a certain way to support operations, but from a business intelligence perspective, the structure should support analysis and integration with data supplied by other participants. There are obvious advantages in maintaining an integrated data layer- the ability to drill down to ‘integrated’ details in one place and less redundancy in transformations that deliver metrics to multiple places (See “reusable metrics” below).
Data modeling paradigm:
The debate about “Kimball vs. Inmon” approaches is almost as old as the concept of data warehousing itself. Both approaches have their merits. Kimball proposes implementing a warehouse using dimensional modeling, where several star schemas (~ business processes) are integrated using conformed dimensions. Data is loaded into the star schemas with limited persistence on the way from the source systems to the target schema. Inmon’s concept of an enterprise data warehouse normalizes data permanently in 3rd norm, before delivering it to users in a star format. Some normalization constraints can be relaxed, since the system is not expected to support transaction processing. The Kimball approach has been steadily gaining popularity for ease of access with less overhead, until organizations started integrating more diverse data: external, unstructured, into in-house data.
The dimensional model primarily assumes that the access patterns of data are predictable, so the data can be structured into dimensions and fact tables. This assumption may not always hold true with a large variety of correlated data, like in a clinical domain. All the relevant metrics and relations cannot be predefined, and exploration for more insights often requires potentially correlated data to coexist as well. A structure based on predefined access paths may violate this requirement. Given the disparate nature of data sources, integration gets complex without a persistent normalized (vs. star schema) data store. In certain cases, vendors providing specialized services (e.g. risk scoring) request data extracts. Having a normalized data store will help to create such extracts faster.
Scalable metrics:
With the ACO metrics from CMS predefined, the ambiguity is reduced, but sometimes at the cost of scalability. When defining granularity for the data model, focusing on the supplied details can prevent using the model for other variants of metric definitions and even related metrics. This can lead to costly rework of revising models, retrofitting code, and regression testing that follows. In the worst case, the model gets littered with tables to accommodate variants. To avoid this issue, define the grain at the right transaction level, in many cases the patient encounter, and derive aggregates as needed to serve any custom requirements. Aggregations can be stored within the database or performed run time.
In the ACO world, readmission and at-risk-population measures are defined for specific performance measurement. Certain exclusions are allowed for compliance credits. But a provider may be interested in analyzing performance beyond, or from, these CMS mandates. Account for these scalability needs as well in the underlying model.
Reusable metrics:
Many clinical measures should be defined once and reused/accessed in many places. This is important for correlation analysis. A holistic view of patient health involves easy access to health records in an integrated fashion. If the measures need to be replicated in multiple tables for accessibility, then the underlying code should be shared to keep the definitions standard across all the tables. How do we “define” a patient’s blood pressure is under control? Which hospital admissions can be excluded from readmission compliance because of specific profiles? If different flavors of a metric are indeed required to support analysis, then these attributes should be named appropriately. Use metadata to describe their purposes clearly.
More on this new model later, and feel free to contact us with your feedback, and questions!




