
Jose Hernandez
1 Year Ago
In my previous post I introduced columnar databases. I never did say why columnar databases were created. Primarily, they were developed to deal with performance, or lack of performance, when trying to query aggregated values from large databases. The culprit of performance issues has typically been disk I/O. That’s right, the last mechanical part of our computers, the hard disk drives. The performance cost of moving the read/write heads around to find and read data is high. The less you have to jump around to find data, the better.
How Columnar Databases Work
Let’s get back to how columnar databases work and do a quick recap. To describe a columnar database, I started with a review of row-based databases as a basis for contrast. I ended with the following example:
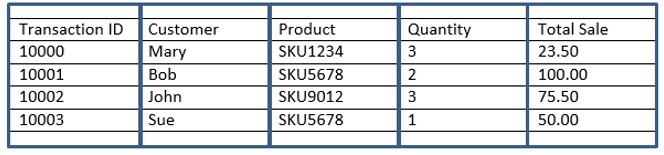
To recap, unlike row-based databases, the data above would be stored like this in a columnar fashion:
10000:10001:10002:10003:Mary:Bob:John:Sue:SKU1234:SKU5678:SKU9012:SKU5678:3:2:3:1:23.50:100.00:75.50:50.00
Notice the data is stored sequentially going down each column (not across each row)! Let’s focus on the Product and the Total Sale columns. The information I am most interested in to answer the original question (What is the total sale for every transaction for the product SKU5678?) is grouped contiguously.
10000:10001:10002:10003:Mary:Bob:John:Sue:SKU1234:SKU5678:SKU9012:SKU5678:3:2:3:1:23.50:100.00:75.50:50.00
This is very powerful when you consider that I only need to process through a subset of the information that makes up the original transaction. By storing the information in a columnar manner, I can ignore fields of information that are not relevant to my question, thus reduce the amount of data the database has to comb through to get the answer. Row-based databases must read every element across each record (row), columnar databases only read the columns that contain the information you are interested in.
As you follow my example here, you might ask yourself, how does the columnar database know which sale entry in the Total Sale column lines up with which product entry in the Product column? The simple answer is that each row in the columns is assigned a row-id. Row 4 in the Product column is the same row as row 4 in the Total Sale column. In my examples here I have not shown the row identifier column as it is not part of my business data set (but it is a system column).
Columnar Database Secrets: Data Compression and Horizontal Partitioning
Now that I have exposed the key difference between row-based and column-based database storage, let’s explore other columnar secrets. While not really secrets, it does sound more mysterious that way- these include data compression and horizontal partitioning.
Data Compression
Let’s start with data compression. Since data in a given column is of the same type or category, there is a certain level of duplication in the data. This lets columnar databases save space by not repeating the same values when contiguously found in a column store. In the example below, instead of storing the value string each time, the string only needs to be stored once and simply referred to in subsequent rows.
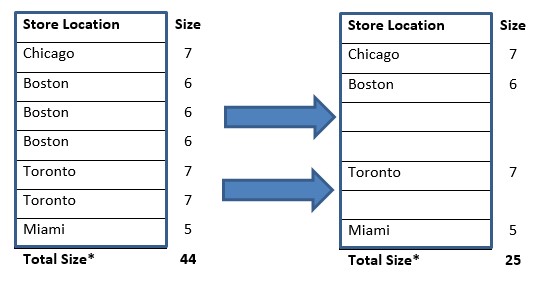
Simplifying the calculation, we will consider each character in the string. The first table requires 44 characters to store the data, while the second table requires 25. The lower the cardinality of a given column, the greater the compression. Think of how much compression is possible if data is ordered in a given column. This could be a real space saver! Different columnar database vendors implement compression in different ways, but conceptually, it’s the same.
*Please keep in mind that the real calculations are not this simple. I am introducing the concept in a simplistic manner.
Horizontal Partitioning
The other interesting technique incorporated in columnar storage is horizontal partitioning. Horizontal partitioning is the concept of dividing up each group of columns into distinct partitions. Each partition has a set of data, and statistics on each partition are kept. These statistics include information on what data can be found in the partition and also, aggregated calculations on the numeric columns. This is very powerful. If the columnar database server knows what is in each partition, it can decide if it should investigate all the data in a partition or simply use the aggregated values and avoid the details!
Different vendors implement this in different ways, but the concept is the same (and yes, once again, I am simplifying the example to make the point). Here a picture is worth a few words, so let’s take a look.
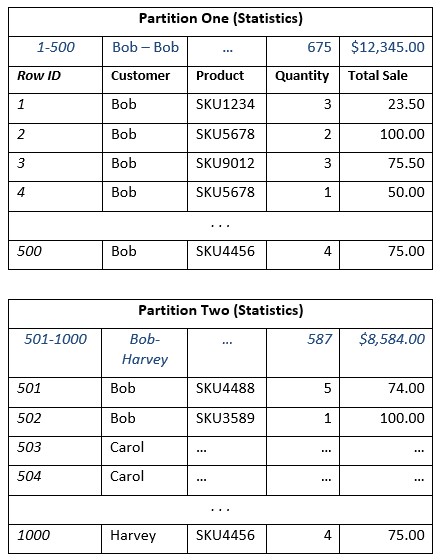
Now, given the example above, what if I asked the question, “How much revenue was generated from Bob?” The answer can be determined by simply looking at the aggregate statistics from Partition One, plus looking at a subset of data in Partition Two.

Notice I only had to hit three places to get my answer; the statistics of Partition One and just two rows in Partition Two. This little technique could provide significant performance gains on queries on very large data sets. While the data set in this example is very small, consider the difference in partitions with millions of rows. Being able to get the answer by simply looking at the statistics for each partition will increase performance greatly! This technique is also implemented in different ways by different vendors, but conceptually, it’s the same.
Wrapping This Up
Database performance is always a challenge. One of the key reasons for these performance challenges has been disk I/O. Columnar databases came about in order to address performance challenges when executing analytical queries on large data sets. When you look at the way transactional data is being stored and the nature of analytical queries requiring us to jump around the stored data, you can begin to imagine that spinning platters with read/write heads flying around would pose a performance problem. Columnar storage addresses some of these issues by re-arranging the way we store and retrieve data on these spinning platters. But technology is constantly changing, especially in disk storage. With solid state drives and in-memory processing, disk I/O isn’t really an issue anymore. I am not saying that we can replace all of our platters with solid state modules now, but we are at the doorstep of that change. So, if a columnar approach solves disk I/O challenges, and these challenges are going to be a thing of the past, are these techniques still required? Yes. New in-memory databases allow you to choose a row-based or column-based approach to storing data. The very cool techniques used to make queries faster (or transactional processing faster) do still apply and even in-memory processing can benefit from these techniques.
I set out to provide insight into columnar databases and I hope that I was able to do that for you. Looking at the concepts explored here, I suspect I have also opened up new questions about columnar data stores. Well, since I need more topics to write about, I will hold off on those topics until another time.
Consider these benefits and drawbacks:
Columnar Benefits
- Columnar databases typically provide better query performance when the number of fields required for the query are a subset of the transaction’s fields
- Columnar databases can provide more efficient use of space (data compression)
Columnar Drawbacks
- Writing transactional data to a columnar database takes more time than to a row-based database (warning, don’t use a columnar store for your transactional systems)
- If your query contains all the columns in a transaction, your query will typically perform worse compared to a row-based database



