
Jose Hernandez
1 Year Ago
Unless you’re a technologist living under a rock… hold that thought, these days the internet is available even under a rock. Unless you have purposely decided to avoid information about databases, you have come across the concept of columnar databases. There are a variety of columnar databases: Sybase IQ, InfoBright, and Redshift, to name a few (there are many others). If you are not sure what columnar databases are, or what their benefits (and weakness are), I hope to shed some light on the subject for you.
What is a Columnar Database?
First, let’s describe what a columnar database is. It is more a concept than a product. From the outside, to an application or a user, you can communicate with these databases using SQL DDL, DML, and DCL commands (just like you do any SQL DBMS). So, a columnar database is, simply a database that stores data in a columns rather than rows, and from the outside looks like your typical row-based DBMS. I am over-simplifying this, and for the moment, this is fine.
Why Do We Need Columnar Databases?
Since these databases look and act, on the outside, like traditional row-based databases, why do we need them? To answer this question, let’s focus on row-based databases (the type of databases we are mostly familiar with).
Row-Based Database Persistence
Long before we worried about business intelligence and analytics, we were focused on transactional applications and storing transactional data. When dealing with transactions, the data for a given event is all relevant as a collection. To describe the transaction, I need all the data that makes up this transaction. That said, it makes sense to store and retrieve this information contiguously as a row. We can logically think of the data as being stored in a row based table (like the example below).

This logical representation doesn’t tell the whole story. What’s really important is how the data is persisted. In a row based database, the data above would be stored sequentially like this (I have added delimiters for readability):
10000:Mary:SKU1234:3:23.50:10001:Bob:SKU5678:2:100.00:10002:John:SKU9012:3:75.50:10003:Sue:SKU5678:1:50.00
Now, looking at this data from a transactional point-of-view this is very efficient. If we were interested in a specific transaction, we simply need to find the start of the record. Once we find the start of a record, the rest of the record can be found in a continuous stream. For example, looking for the transaction 10002:
10000:Mary:SKU1234:3:23.50:10001:Bob:SKU5678:2:100.00:10002:John:SKU9012:3:75.50:10003:Sue:SKU5678:1:50.00
Limitations of Row-Based Databases
But what if we wanted the total sale for every transaction for the product SKU5678? This is a different type of question. We are not interested in the details of a given transaction, but the sum of the Total Sale of transactions that involved the specific Product SKU5678.

Where is the data, we need to find that answer? Let’s look at our example below (highlighted in yellow):
10000:Mary:SKU1234:3:23.50:10001:Bob:SKU5678:2:100.00:10002:John:SKU9012:3:75.50:10003:Sue:SKU5678:1:50.00
Further notice that we really only need some of that information to get the result (highlighted in blue):
10000:Mary:SKU1234:3:23.50:10001:Bob:SKU5678:2:100.00:10002:John:SKU9012:3:75.50:10003:Sue:SKU5678:1:50.00
Columnar Approach
In order to get the information we need, we are no longer dealing with a continuous stream, instead, we are jumping around the data set. With that, let’s turn our attention to a columnar approach, how it is different, and what’s going on under the covers. The first thing to note is that we think of data as being stored in columns instead of rows.
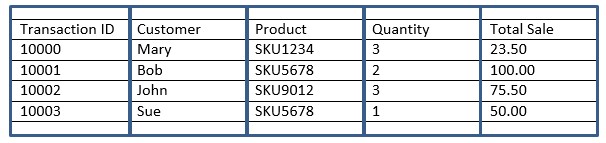
Unlike a row based database, the data above would be stored like this (I have added delimiters for readability):
10000:10001:10002:10003:Mary:Bob:John:Sue:SKU1234:SKU5678:SKU9012:SKU5678:3:2:3:1:23.50:100.00:75.50:50.00
compare that to our row-based storage (I will repeat it here for convenience):
10000:Mary:SKU1234:3:23.50:10001:Bob:SKU5678:2:100.00:10002:John:SKU9012:3:75.50:10003:Sue:SKU5678:1:50.00
Conclusion
Notice the data is stored sequentially going down each column (not across each row)! Now that the stage is set, I will dive into the columnar approach in my next Blog. Stay tuned!



